
Have you ever wondered how exactly a computer stores letters like A, B, C… or Chinese characters like 吃, or even some emojis like 😆 and 🚀?
Maybe you are familiar with ASCII and you are aware of Unicode, but you don’t know exactly how it works?
In this article, we’ll cover the basics of character encoding and several encoding schemes and introduce some fundamental concepts on the way.
Evolution of data transmission
Back in the day, when people wanted to communicate over great distances, they had limited options. They could write messages in a form of mail letters and send them over via post service or even use pigeons to fly and carry them over.
But still, there was a need for immediate communication in cases of emergency like the warning of bad weather, or military communication.
Over time different civilizations developed quite a few techniques of communication such as smoke signals, church bells, whistling, reflecting sunlight with mirrors, etc. All of these were limited in their capabilities and were generally not suitable for transferring arbitrary messages. They were mostly used to signal if there is some kind of danger ahead or call for help.
Improved ways of communicating arbitrary messages are called Telegraphy.
Telegraphy is the long-distance transmission of messages where the sender uses symbolic codes, known to the recipient, rather than a physical exchange of an object bearing the message.
Some of the most used and famous telegraph systems are the Morse code and Flag semaphore (used in maritime and aviation even in the present time).
As good as they are, these systems were not suitable for computer processing.
Character encoding
Encoding is a way to convert data from one format to another.
As we all know, computer stores data in a binary format, i.e. ones and zeros. So, to store textual data in computer memory, or transfer it over a digital network, we need a way to represent textual data in a binary format that the computer understands.
A single unit of textual data is called a character (or char in most programming languages). For now, it’s enough to know that char can be any sign used for creating textual content, such as a letter of the English alphabet, digit, or some other signs like space, comma, exclamation mark, question mark, etc.
A character encoding is a way to convert text data into binary numbers.
Essentially, encoding is a process of assigning unique numeric values to specific characters and converting those numbers into binary language. These binary numbers later can be converted back (or decoded) to original characters based on their values.
Character set is simply a mapping between binary numbers and characters.
Simply put, character set is an agreement that defines the correlation between binary numbers and characters from a character set.
Creating character set
What would you do if you were to make up your character set for the English language?
Probably you would take all letters from the English alphabet both upper and lower case:
1
AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz
Then, you would add digits as well:
1
0123456789
Also, you would need space, comma, semicolon, and other signs that complement letters and digits:
1
<space>!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
If you count these up, you will get 95 distinct characters:
1
AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789 !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
To represent 95 characters, we need at least 7 bits, which allows us to define 2^7 = 128 characters.
Now, we can make up a table that will contain the mapping between each binary number and character from the set we just defined.
We could make A = 0000 0001, B = 0000 0010 and so on… Or in any other way we like.
What are fonts 🤔?
Most surely you heard of and used many different fonts on a computer. It must be obvious by now, that the character set is only defining what is sent, not how it looks.
When we are referring to a character as “A” or “B”, we have a common understanding of what it means (it’s the Platonic “idea” of a particular character). But we can all read and write the same characters in different variations (shapes).
A font is a collection of glyph definitions, in other words, the shapes (or images) that are associated with the character they represent.
Simple as that 🙂.
ASCII
We’ve shown that at least 7 bits are needed to represent characters used for creating textual content in the English alphabet.
As with most things in engineering, character sets (encodings) should be standardized.
One such (most famous) 7-bit encoding is ASCII (based on Telegraph code).
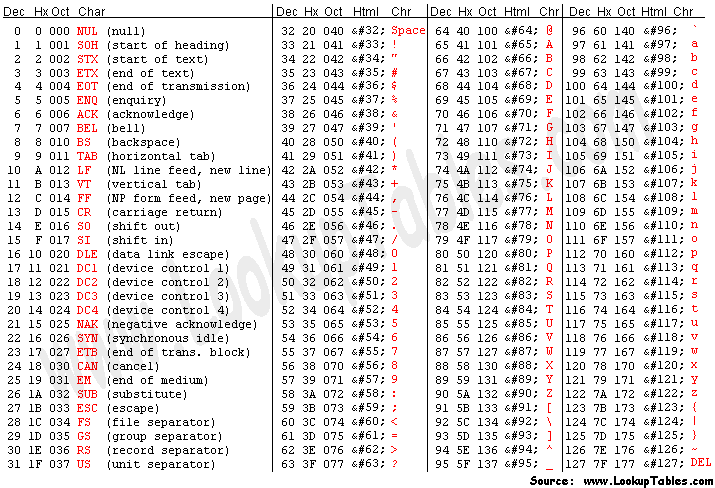
ASCII table has arranged characters in a very elegant fashion.
For example, all the uppercase and lowercase letters are in their alphabetical order. The same goes for digits.
You can easily learn ASCII code for the character A, character a and character 0 because they are arranged in such an elegant way:
- Character
Astarts with 1, followed by all zeros and 1 (as the first letter in the alphabet) at the end: 100 0001 - Lower case letters have the same ASCII codes as upper case letters, with the second digit being 1 instead of 0. It’s easy now to find
a- just takeA1000001 and flip the second digit to 1, you get 110 0001 - Digit zero is 010 0000
A summary of these characters is given here in a table:
| Character | Binary representation | Rule |
|---|---|---|
| A | 100 0001 | Starts with 1, has all zeros, and 1 at the end |
| a | 110 0001 | Starts with 11, has all zeros and 1 at the end |
| 0 | 010 0000 | Starts with 01, has all zeros |
Now you can derive any other letter/digit by simply counting up to the one you need.
CR and LF
Extra 35 spaces were used to represent some special, so-called “control” characters.
Some would be BS (backspace), DEL (delete), TAB (horizontal tab).
Let’s take a look at two particularly interesting examples. Namely, telegraph machines would require 2 operations to go to the next line when printing text:
CR - Carriage return
LF - Line feed
It’s based on manual typewriter machines like this one:

When you type text and come to the right end of the page, you would like to go to the next line.
So, you would first push the handle on the left side (marked as 1 on the picture) to the right to move the carriage, hence CR (Carriage return).
The next step is to “feed” the typewriter with more next line of paper with a knob either on the right end of the carriage (market as 2 on the picture). Hence, LF (Line feed).
This brought confusion to users of different OS, as there is no standardized end-of-line notation:
| Operating system | End-of-line notation |
|---|---|
| Linux | LF |
| Windows | CR LF |
| MAC (up through version 9) | CR |
| MAC OS X | LF |
In most programming languages non-printable characters are represented using so-called escaped character notation, usually with a backslash character \.
Some examples are given here:
| Character | Escaped |
|---|---|
CR | \r |
LF | \n |
TAB | \t |
ASCII encoding example
Let’s now try to encode text Hello World! in ASCII.
It would get you something like this:
| Character | Dec | Hex | Binary |
|---|---|---|---|
| H | 72 | 48 | 100 1000 |
| e | 101 | 65 | 110 0101 |
| l | 108 | 6c | 110 1100 |
| l | 108 | 6c | 110 1100 |
| o | 111 | 6f | 110 1111 |
| <space> | 32 | 20 | 010 0000 |
| W | 87 | 57 | 101 0111 |
| o | 111 | 6f | 110 1111 |
| r | 114 | 72 | 111 0010 |
| l | 108 | 6c | 110 1100 |
| d | 100 | 64 | 110 0100 |
| ! | 33 | 21 | 010 0001 |
What about the 8th bit?
A byte is the smallest unit of storage that a computer would use. You may think that since the beginnings of the computing era byte was always 8 bits long. But that is not the case, as you can see with ASCII, which uses 7 bits. ASCII was standardized in 1963, but the first commercial 8-bit CPU came out in 1972. And as late as 1993 it was formally standardized that a byte is 8 bits long.
For modern CPUs byte is 8 bits long, so when storing ASCII characters, you are left with one extra bit.
All original text encoded with 7-bit ASCII can be encoded in 8-bit simply by appending 0 to the left side of the binary code, so its decimal and hexadecimal value stay the same.
Now, taking our last example we can finally write it in the 8-bit format:
1
2
H e l l o <space> W o r l d !
01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100 00100001
One question arises here: can we somehow leverage this extra bit 🤔?
This 8th bit allows us to have another 128 spaces for new characters, right?
Extended ASCII (Code pages)
Encodings that are using same mappings for ASCII printable characters are called Extended ASCII and are commonly referred to as Code pages. They guarantee that all ASCII encoded files can be processed with these extended encodings.
One popular 8-bit encoding scheme that was not ASCII compatible is EBCDIC, which was used on proprietary IBM PCs.
Instead of just one, we have a huge number of standardized code pages. A full list of code pages can be found on Wikipedia: https://en.wikipedia.org/wiki/Code_page
Some of the most known are:
Window-1252 (or ANSI-1252) - default code page for legacy Windows OS
![Windows 1252]()
CP437 (also known as OEM 437, or DOS Latin the US) - an original code page for IBM PC.
![CP 437]()
ISO-8859-1, aka Latin-1 (also useful for any Western European language)
![ISO-8859-1]()
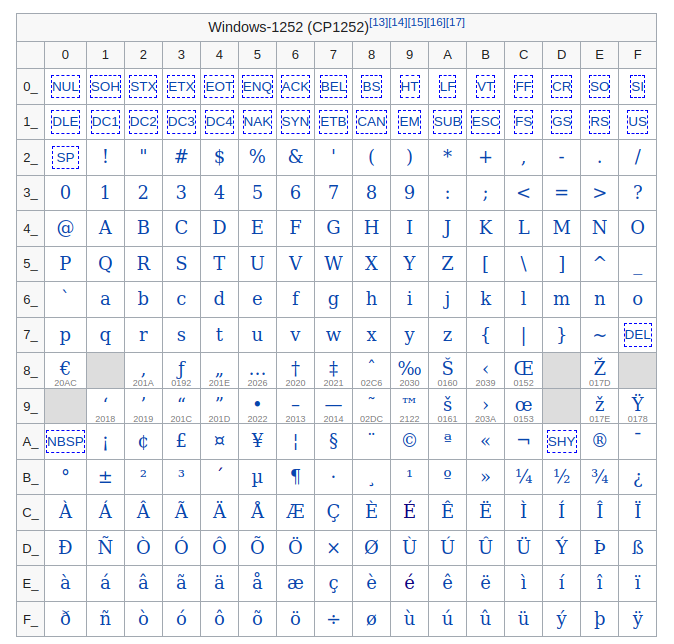

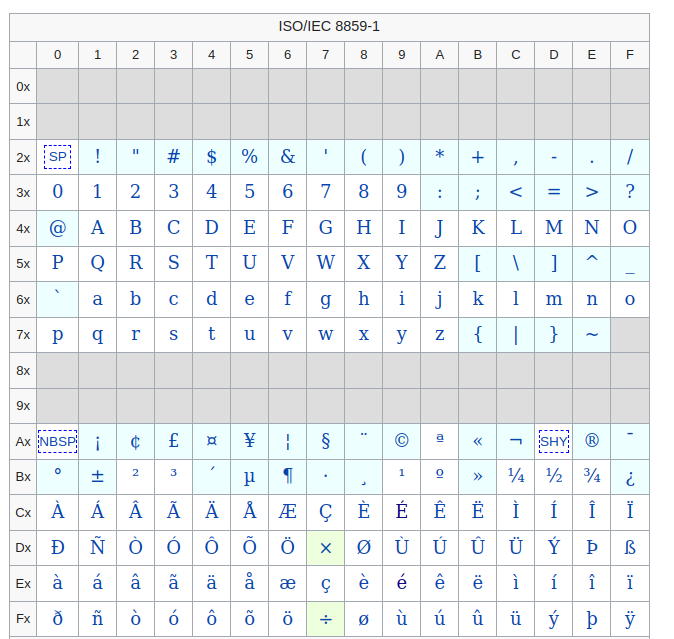
Now, if you wanted to write textual content using Cyrillic you would use Windows-1251 encoding. When you transmit this data, the other party would need to use the same encoding scheme (code page) to successfully read the data they received. If the encoding scheme is not the same, the text would appear as if written in a different language.
If not explicitly set, ISO 8859–1 was the default encoding of the document delivered via HTTP with the MIME Type beginning with text/. Since HTML5 this was changed to UTF-8.
Unicode
Code pages solved only part of the problem - storing additional characters for other languages since ASCII was designed to be sufficient for the English alphabet.
For most European languages this was acceptable, but not a great solution. You could not for example write in multiple languages in the same textual file, because you can use only one code page while processing text.
A bigger issue than that was the lack of support for languages that have much more characters than available 128 spaces within ASCII extended 8-bit code pages. Some examples are Arabic, Hindu, and Chinese (which have more than 10 thousand symbols called ideograms, which are actual words rather than letters as we are used to in European languages for example).
In a response to all the problems “code pages” had been introduced, and a new standard was initiated named Unicode. It was an attempt to make a huge single character set for all spoken languages and even some made-up ones and other signs such as emojis 🎉. The first version came out in 1991 and had many new versions since then, the latest one being in 2021 at the time of this writing. The Unicode Consortium also maintains the standard for UTF (Unicode Transformation Format) encodings. More on this later. But first…
Grapheme and code point
Up until now, we described all characters as self-contained symbols that can be represented with a single binary number in the encoding schema.
In simple words, the letter A is just encoded with some binary number (0100 0001 in ASCII).
But, things got a lot more complicated when considering other languages.
Some languages have modifiers of the letters such as accent modifiers. One such example that is also used in the English language for some foreign words is É (e-acute) which is an ordinary E letter with the acute symbol (that forward slash above the letter).
Diacritic - extra decoration for the character
Grammar of some languages requires the use of diacritics for letters when certain conditions are met. Therefore, term character became ambiguous, so a new term is adopted for describing written symbols that could be with or without diacritics - a grapheme.
Grapheme is a single unit of human writing system. It may consist of one or more code points.
As there can be a huge number of combinations of letters and their possible modifiers, instead of making an encoding schema for all of them, it’s much more efficient to encode them separately. Therefore we separate grapheme in code points.
Code point is any written symbol or it’s modifier like diacritic for letters, or even skin color of emojis
So, one or more code points can make up a grapheme. Therefore, the Unicode character set is defined as a set of code points rather than a set of graphemes.
Some people believe that Unicode is just a simple 16-bit code where each character is mapped to a 16-bit number and so there are 2^16 = 65 536 possible code points. That is not the case and there are 144 697 defined characters at the time of writing this article.
What is true is that all characters that can fit into 2 bytes, in other words, 2^16 = 65 536 code points are considered to make up BMP - basic multilingual plane (U+0000 to U+FFFF). This was the first attempt to unite all code points needed for storing textual data, but soon it became obvious that it needed even more space, so 2 bytes were not sufficient anymore.
Let’s go back to É for a moment. This particular symbol can be encoded in two ways:
using one code point that represents character É (U+00C9)
using two code points, one for the letter E (U+0065) and its accent modifier (U+02CA)
Codepoint notation
As we’ve seen, the usual notation for Unicode characters is following:
1
U+XXYY
U+stands forUnicodeXXYYare bytes expressed in hexadecimal numbers (can be two or more)
If we go back to É described as 2 code points, we can easily track the first code point as hexadecimal 65, which is indeed the letter E in the ASCII table.
Some graphemes have more than 2 bytes. For example thumbs up emoji 👍 has the notation: U+1F44D.
Unicode encoding strategies
ASCII has a very simple encoding scheme. As it uses only one byte, it’s very easy to map all characters to binary format and vice-versa.
For Unicode, things are not that simple. There are varying lengths of code points, going from 1 up to 4 bytes in size.
Next, we’ll take a look at the most interesting encoding schemes for Unicode. There are two groups of schemes:
- UCS - Universal Character Set
- UTF - Unicode Transformation Format
There are similarities and differences between them. We’ll cover the most relevant in this article.
UTF-32 and UCS-4
As the name suggests, UTF-32 consists of 32 bits, i.e. 4 bytes. This is the simplest encoding strategy. Every code point is converted to a 32-bit value. We’ll see in short why this strategy is not very efficient in terms of space.
UCS-4 is the same in every aspect as UTF-32.
Let’s go back to our example from the beginning of this article with a simple change: let’s add emoji 🚀 between world and !:
1
Hello world🚀!
| Character | Hex |
|---|---|
| H | 00 00 00 48 |
| e | 00 00 00 65 |
| l | 00 00 00 6c |
| l | 00 00 00 6c |
| o | 00 00 00 6f |
| <space> | 00 00 00 20 |
| W | 00 00 00 57 |
| o | 00 00 00 6f |
| r | 00 00 00 72 |
| l | 00 00 00 6c |
| d | 00 00 00 64 |
| 🚀 | 00 01 F4 4D |
| ! | 00 00 00 21 |
Do you notice something? For the majority of the content, we use much more space than needed. All ASCII characters require just one byte of space, but here we are spending additional 3 bytes per code point, which are all zeros. In other words, UTF-32 wastes a lot of memory for ASCII characters. If the text consists of only ASCII characters, UTF-32 would be 4X larger than the ASCII representation of the same text!
One advantage that UTF-32 has over other Unicode encoding schemes is that because of its simplicity, it’s easy to index code points in a file. As you only need to go 4 bytes per code point, so you can go to the desired index very fast, in both the forward and backward directions.
What happens case when the ASCII text processor tries to read out UCS-4 encoded string? In ASCII text processors, the end of a string is usually presented with 0x00, which means that string is going to be terminated once it comes across a byte that has all zeros. So, it would not read the text till the end if it consists of code points that are less than 4 bytes in size.
UTF-32/UCS-4 is not in use anymore by modern text processors, instead, you will find UTF-16 or UTF-8.
UCS-2
Remember BMP (Basic Multilingual Plane)? We said that all characters that fit into 2 bytes are considered to be part of BMP. UCS-2 was exactly that - 2 bytes per code-point and nothing more!
As this was an improvement over 8-bit code pages, it’s still not enough to represent more and more demanding and ever-expanding Unicode character set, so it quickly became obsolete in favor of a more flexible, yet very similar UTF-16 encoding scheme.
Here is a quick overview of support for code points using different encoding schemes:
| Code point | Binary value | ASCII support | UCS-2 support | UTF-32 / UTF-16 / UTF-8 support |
|---|---|---|---|---|
| E | 01000101 | ✅ | ✅ | ✅ |
| Φ | 00000011 10100110 | ❌ | ✅ | ✅ |
| 🚀 | 00000000 00000001 11110110 10000000 | ❌ | ❌ | ✅ |
UTF-16
This encoding scheme uses either 2 or 4 bytes to represent a single code point, so it’s not limited to UCS-2 to only 65 536 code points.
The majority of the code points that takes up to 16 bits can be directly converted in the same way as UCS-2 is doing - just a simple binary representation of the code point hexadecimal value.
The mechanism it uses is called surrogate pairs.
Surrogate pairs
It’s easier to look at an example of how a code point is encoded with the UTF-16 encoding scheme.
Let’s take emoji like 🚀 that has Unicode value U+1F680.
Its binary form is:
1
00000000 00000001 11110110 10000000
Now, we see that it goes over 16 bits in size. To represent a character of more than 16 bits in size, we need to use a “surrogate pair”, with which we get a single supplementary character. The first (high) surrogate is a 16-bit code value in the range U+D800 to U+DBFF, and the second (low) surrogate is a 16-bit code value in the range U+DC00 to U+DFFF.
1
2
High surrogate format: 110110XX XXXXXXXX
Low surrogate format: 110111XX XXXXXXXX
High and low surrogate pairs exist so we can know if we are in the middle of the character when parsing data encoded in UTF-16.
Now, we need to subtract 1 00000000 00000000 from the binary representation of emoji.
1
2
3
4
00000000 00000001 11110110 10000000
- 00000000 00000001 00000000 00000000
= 00000000 00000000 11110110 10000000
Then, we are going to take the lower 20 binary digits:
1
0000 11110110 10000000
And replace X signs in high and low surrogate with bits we just calculated:
1
2
3
4
5
6
7
8
9
10
11
12
0000 11110110 10000000
// Split in half:
00 00111101
10 10000000
// Replace Xs in High and Low surrogate
High surrogate mask: 110110XX XXXXXXXX
Low surrogate mask: 110111XX XXXXXXXX
High surrogate value: 11011000 00111101
Low surrogate value: 11011110 10000000
And there you have it! Emoji 🚀 is represented in UTF-16 encoding schemes with 4 bytes:
1
11011000 00111101 11011110 10000000
Unicode restricted code points
It’s important to note that since we are using surrogate pairs for marking 4-byte UTF-16 code points, we cannot use ranges for a high and low surrogate for 16-bit code points:
1
2
High surrogate unavailable range: 11011000 00000000 (D800) to 11011011 11111111 (DBFF)
Low surrogate unavailable range: 11011100 00000000 (DC00) to 11011111 11111111 (DFFF)
You can notice that these two ranges makes one continuous range:
1
Surrogate unavailable range: 11011000 00000000 (D800) to 11011111 11111111 (DFFF)
In this range, there are no code points, in other words, this hole makes 2^11 = 2048 unavailable code points.
Because of these restrictions, designers of the Unicode standard decided to exclude the same range of code points from UCS-2, so UTF-16 is fully compatible with UCS-2 for all 2-byte-sized code points.
This restricted range is the same for all Unicode encodings.
Unicode table
The site https://unicode-table.com/ contains a lot of useful information regarding Unicode characters. We can even check the info page for 🚀 emoji here: https://unicode-table.com/en/1F680/ to verify we get the correct value for our example for UTF-16 encoding.

Here we can see basic info, like:
- Unicode value
- HTML code (essentially a decimal value)
- CSS-code (hexadecimal value in a different format than Unicode notation)
Near the end of the page, you can check out Encoding values for this Unicode code point:
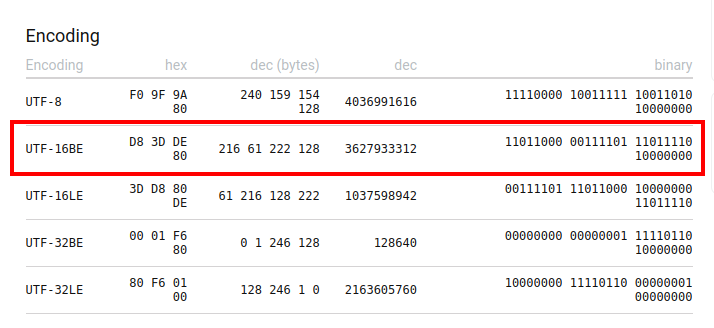
As you can see, we successfully calculated UTF-16 encoding, yeah 🥳!
But wait, you might ask what are now these 2 variations of UTF-16 called UTF-16BE and UTF-16LE 🤔? That brings us to the next topic…..
Endianness
The order of the bytes for multi-byte in which they are stored in memory is called Endianness of the computer system. Depending on the place of the MSB (Most Significant Byte) and LSB (Least Significant Byte) there are:
BE- Big-endian (MSBis stored at the smallest memory address)LE- Little-endian (LSBis stored at the smallest memory address)
Why does this matter in the first place?
CPU usually does not take one byte when processing data, but it takes multiple bytes. This measure is called word in CPU terminology. It becomes natural that the size word is multiple of 8 since the smallest unit for storage is byte (8 bits). Modern CPUs are 32-bit or 64-bit in size.
Most modern computer systems (Intel processors for example) use a little-endian format to store the data in the memory. The reason is beyond the scope of this article, but it’s related to the internal structure of the CPU since particular endianness allows for certain features on different CPU designs.
If we have 32-bit integer number like 42 for example, we would write it in binary format as:
1
2
3
4
5
6
7
8
9
10
// Big Endian
MSB LSB
0000 0000 | 0000 0000 | 0000 0000 | 0010 1010 <- binary representation
0x00 | 0x01 | 0x02 | 0x03 <- memory address
// Little Endian
LSB MSB
0010 1010 | 0000 0000 | 0000 0000 | 0000 0000 <- binary representation
0x00 | 0x01 | 0x02 | 0x03 <- memory address
Now, you can see that if we didn’t know what was the endianness, we could interpret this integer number in the wrong way.
For our example, instead of reading 42, we could by mistake think it’s 704 643 072!
Now that you understand the implications of using the wrong endian in processing data, let’s go back to Unicode.
Text processors need to know how to parse the text. That’s where Endianness comes into the picture.
All Unicode encodings use at least 2 bytes of data per code point, meaning that the CPU is storing multiple bytes at once in either BE or LE.
BOM - Byte Order Mark
A little trick we can use to make sure proper endianness is applied when reading files written in Unicode encodings is the so-called Byte Order Mark or BOM for short.
Let’s take a look at the UTF-16 example.
BOM is nothing more than a code point that has a special property.
Its Unicode value is U+FEFF and it represents “zero-width, non-breaking space”.
What that means is this code point is not visible on screen, yet it is a valid code point for UTF-16 encoding.
But, the catch is that if we reverse the order of the bytes to U+FFFE we get to a value that is considered invalid for UTF-16 encoding. Hence, the text processor understands that it needs to read the bytes in a different order, using Little Endian.
What a nice little trick 🙂!
To use BOM, these 2 bytes will be saved at the beginning of a file, so the text processor can immediately figure out what Endianness is used for the file.
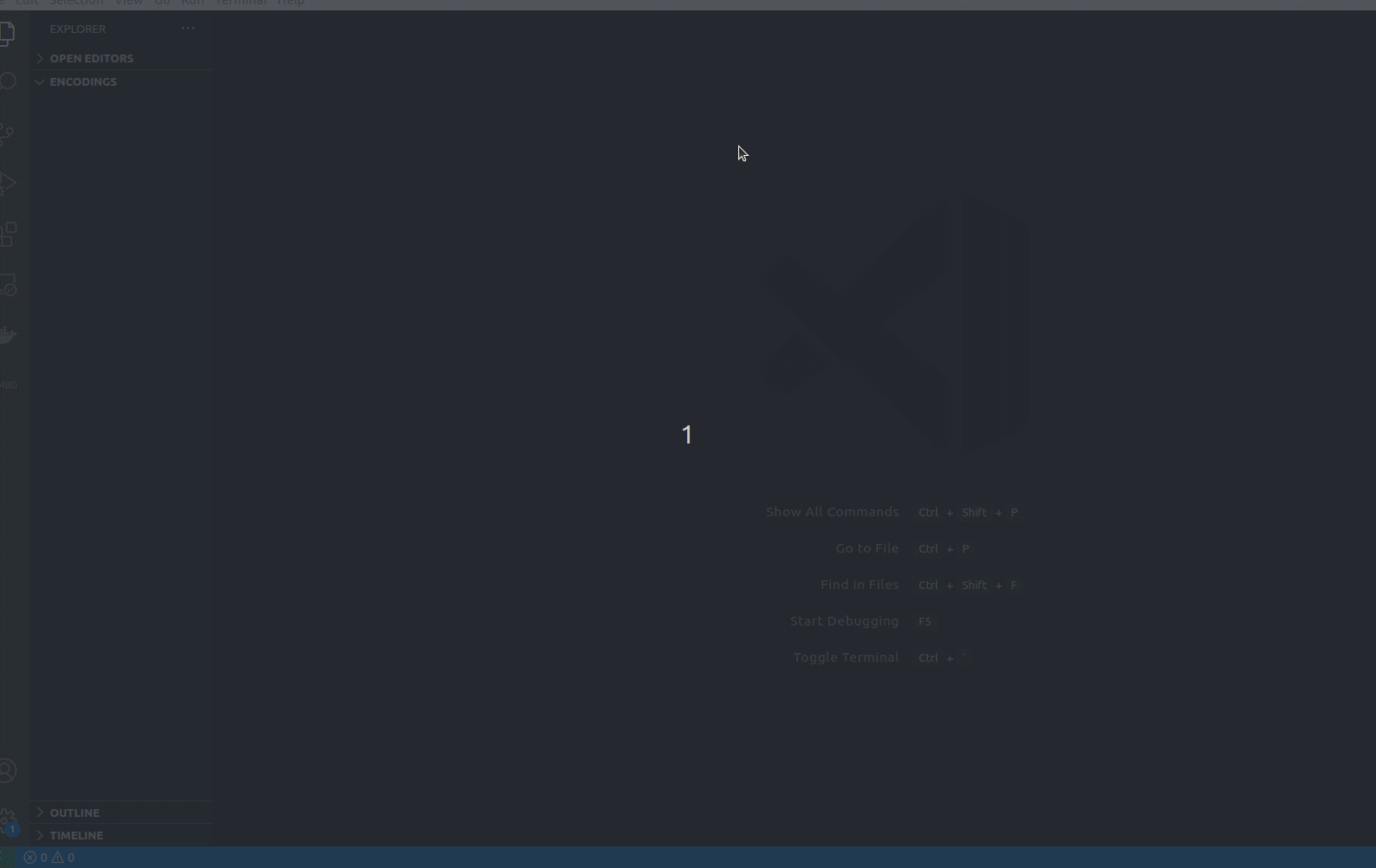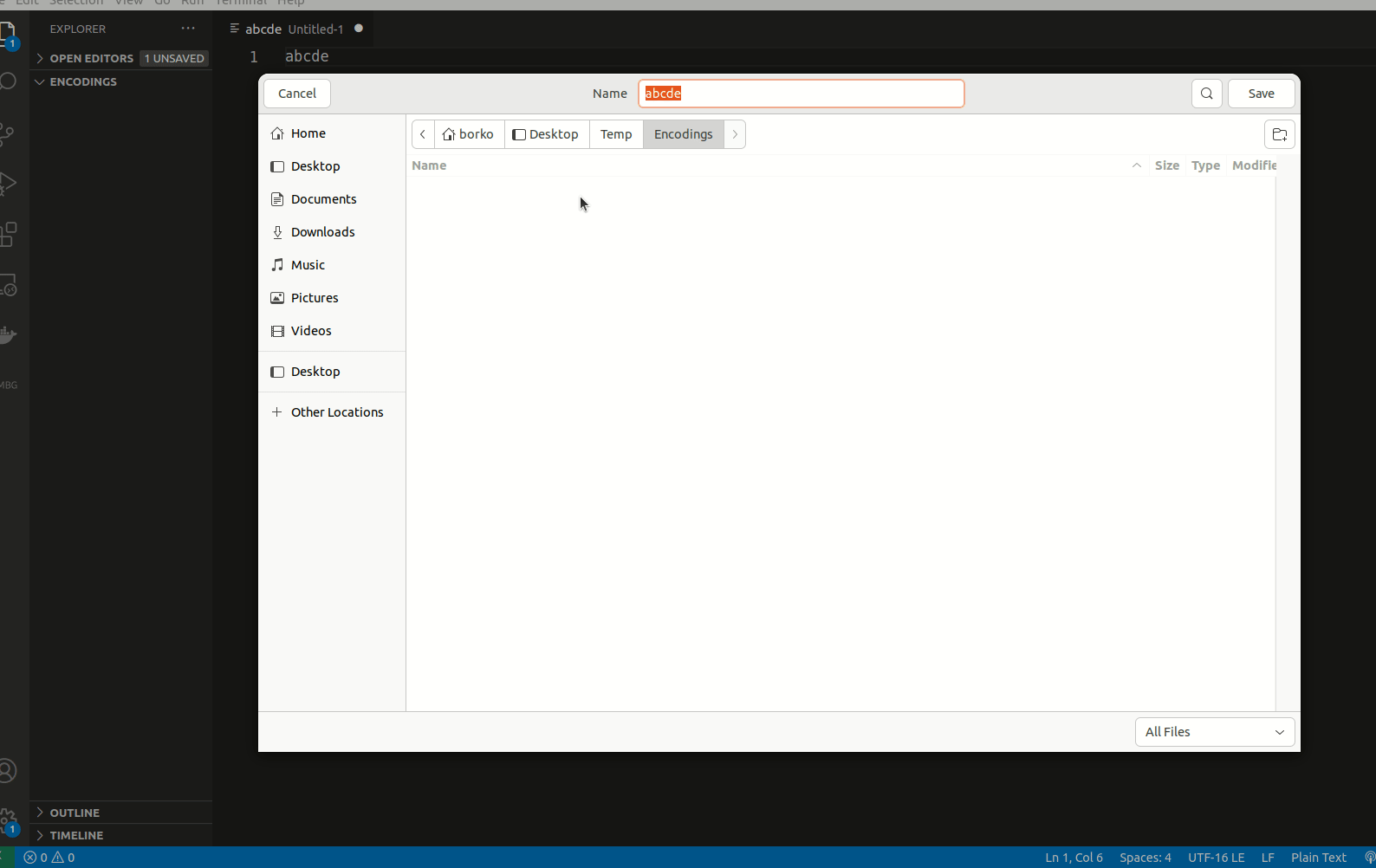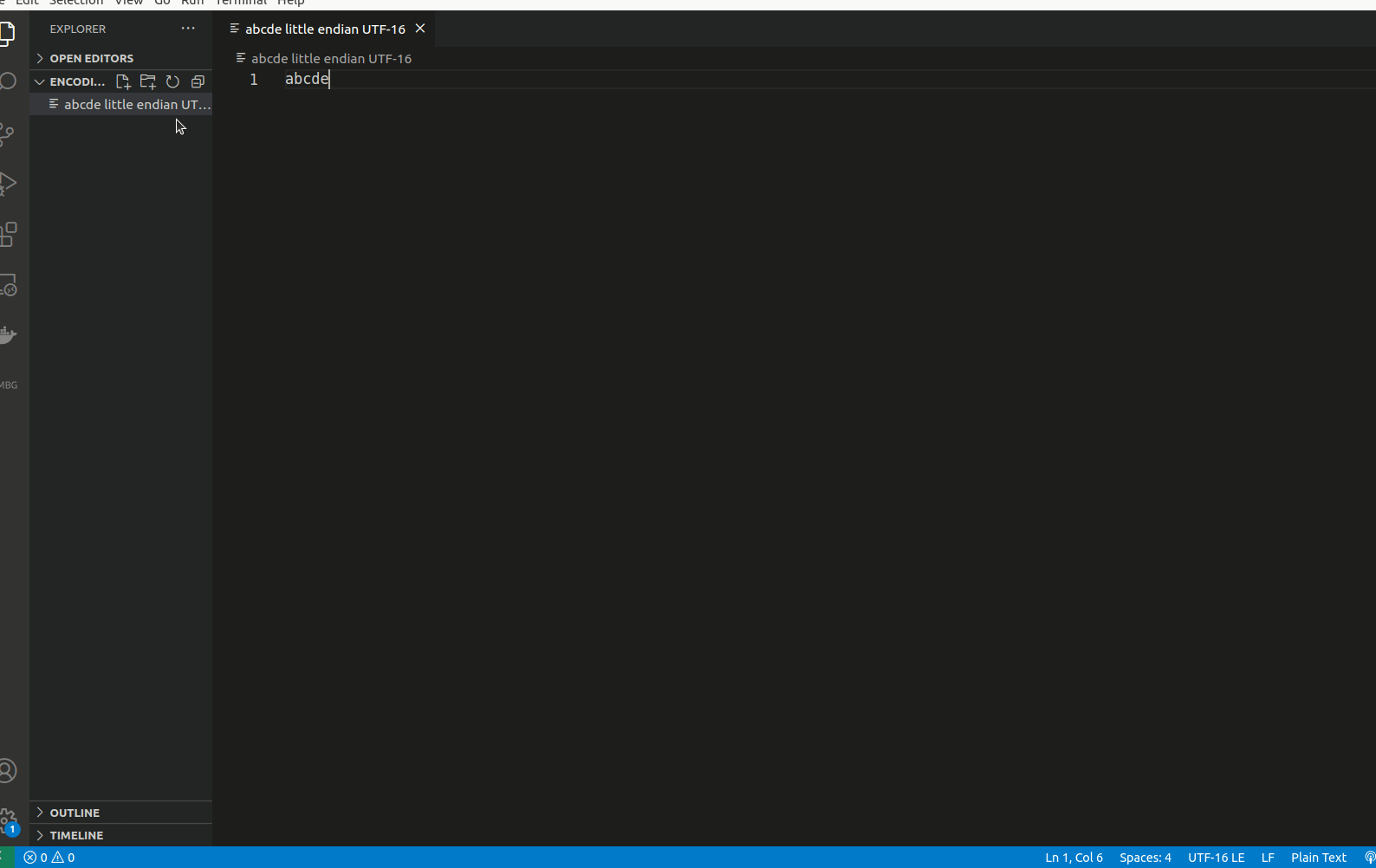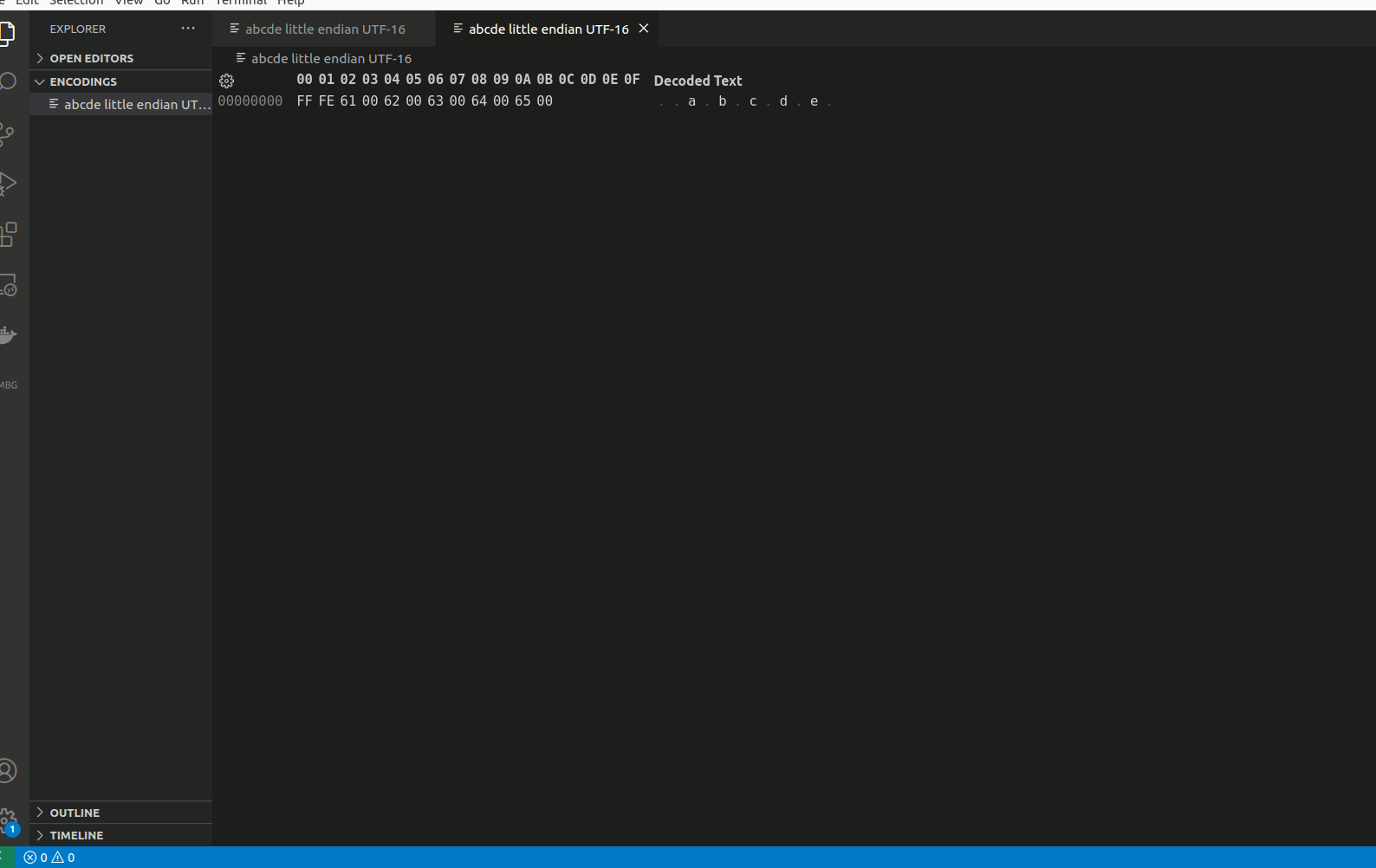
Now, to demonstrate this, I will show how it looks when saving characters abcde in a file using UTF-16 LE and UTF-16 BE:
1
2
3
// When saved as UTF-16 LE it will keep LSB on lowest memory address
FF FE 61 00 62 00 63 00 64 00 65 00
1
2
3
// When saved as UTF-16 BE it will keep LSB on lowest memory address
FF FE 61 00 62 00 63 00 64 00 65 00
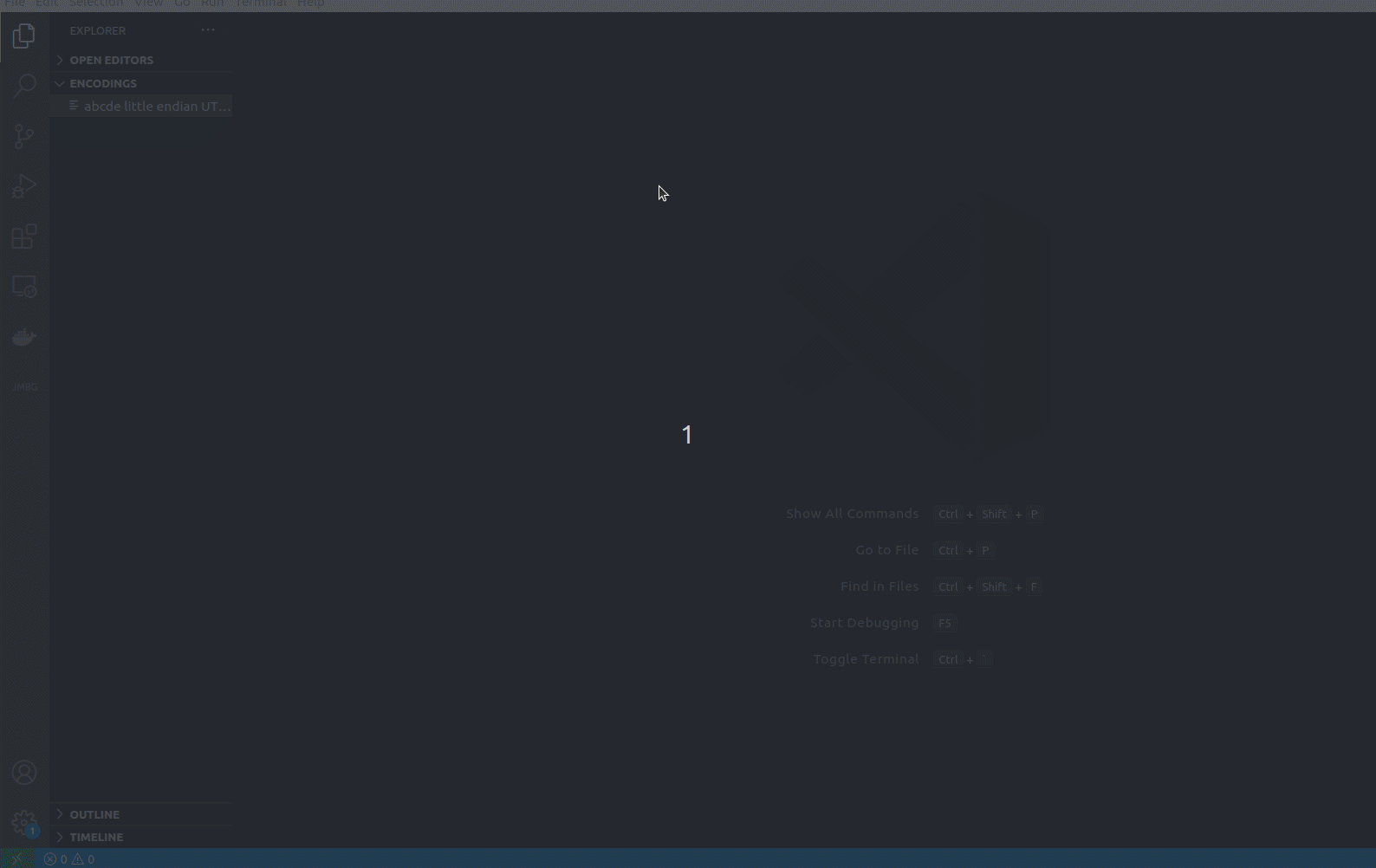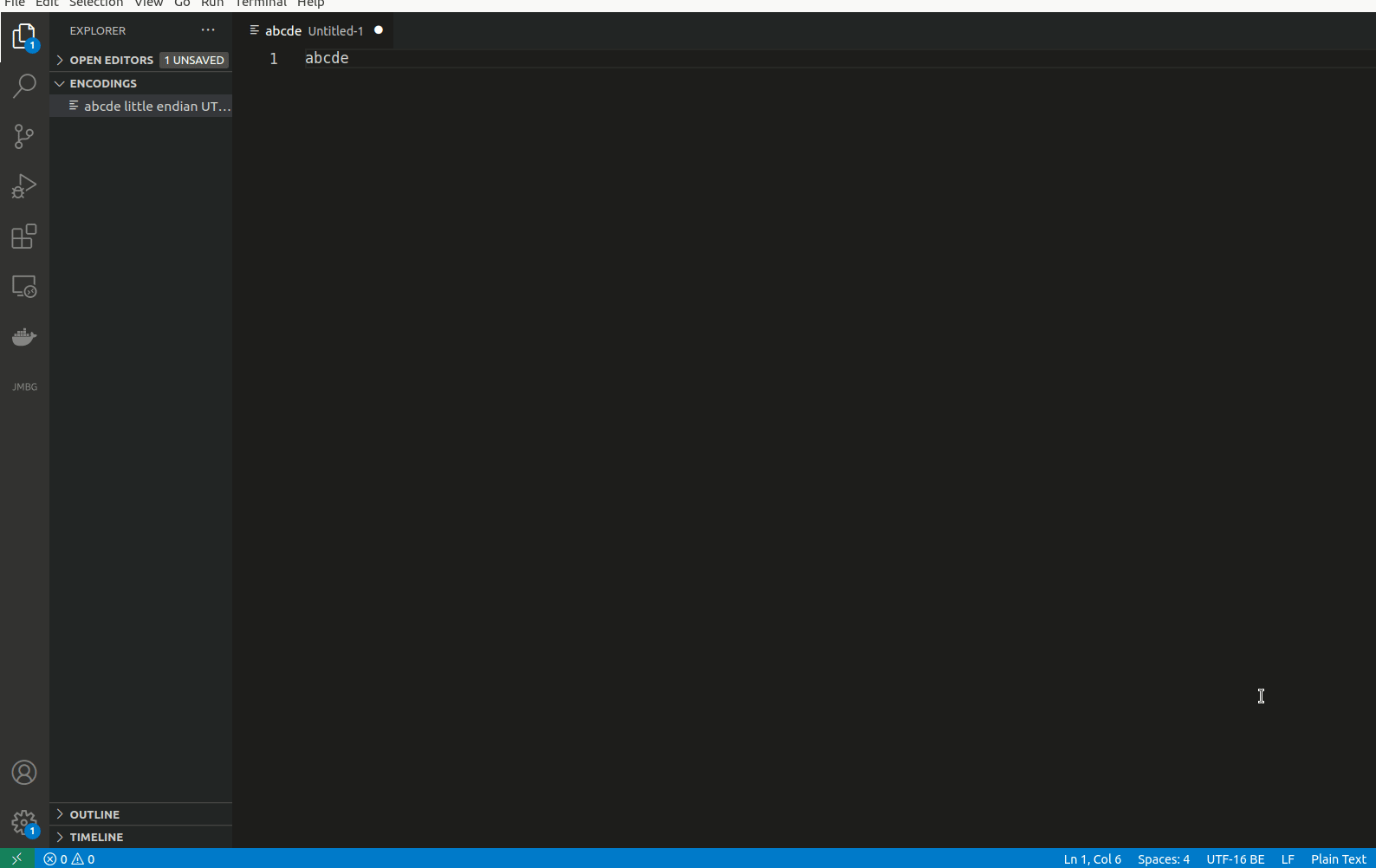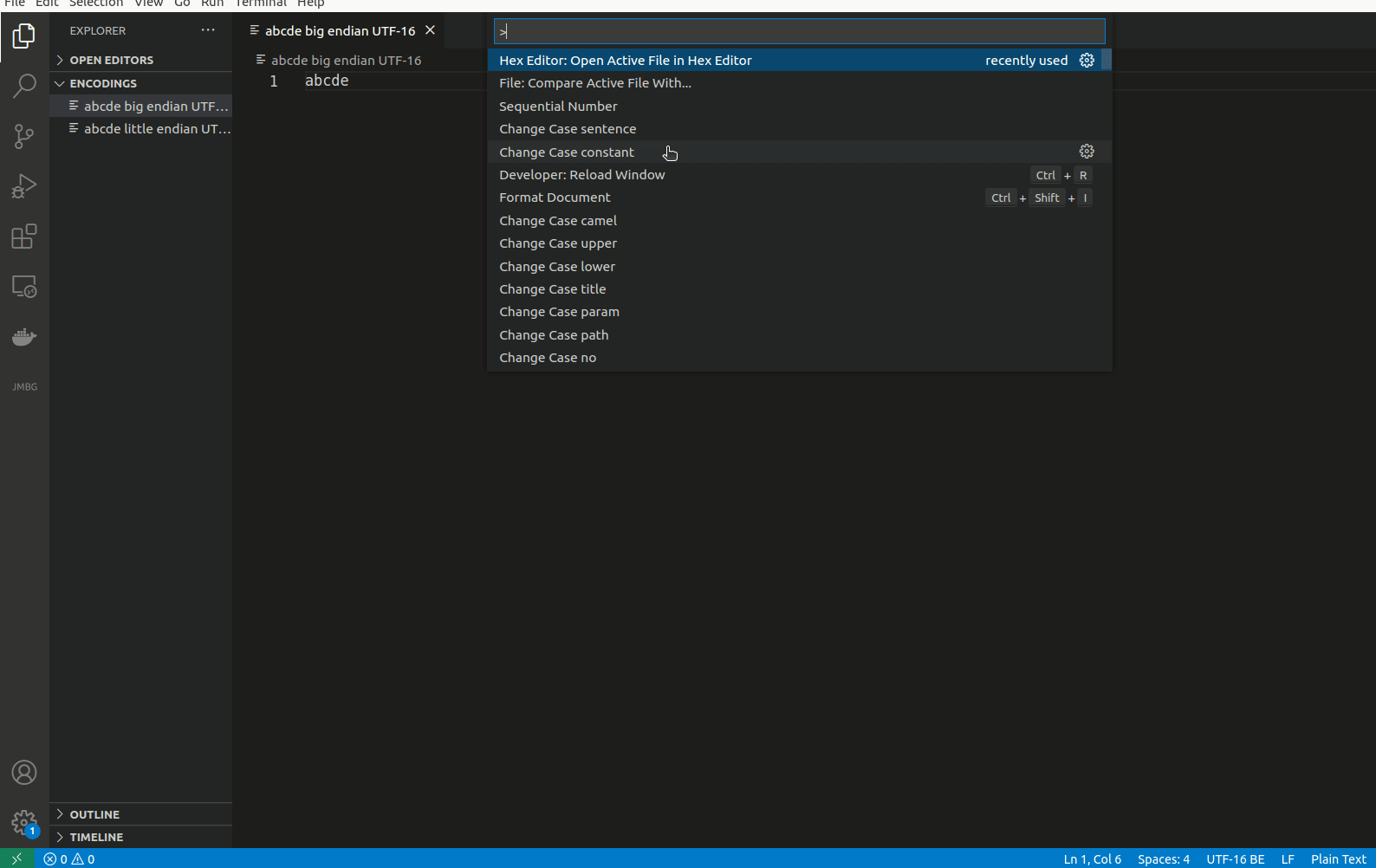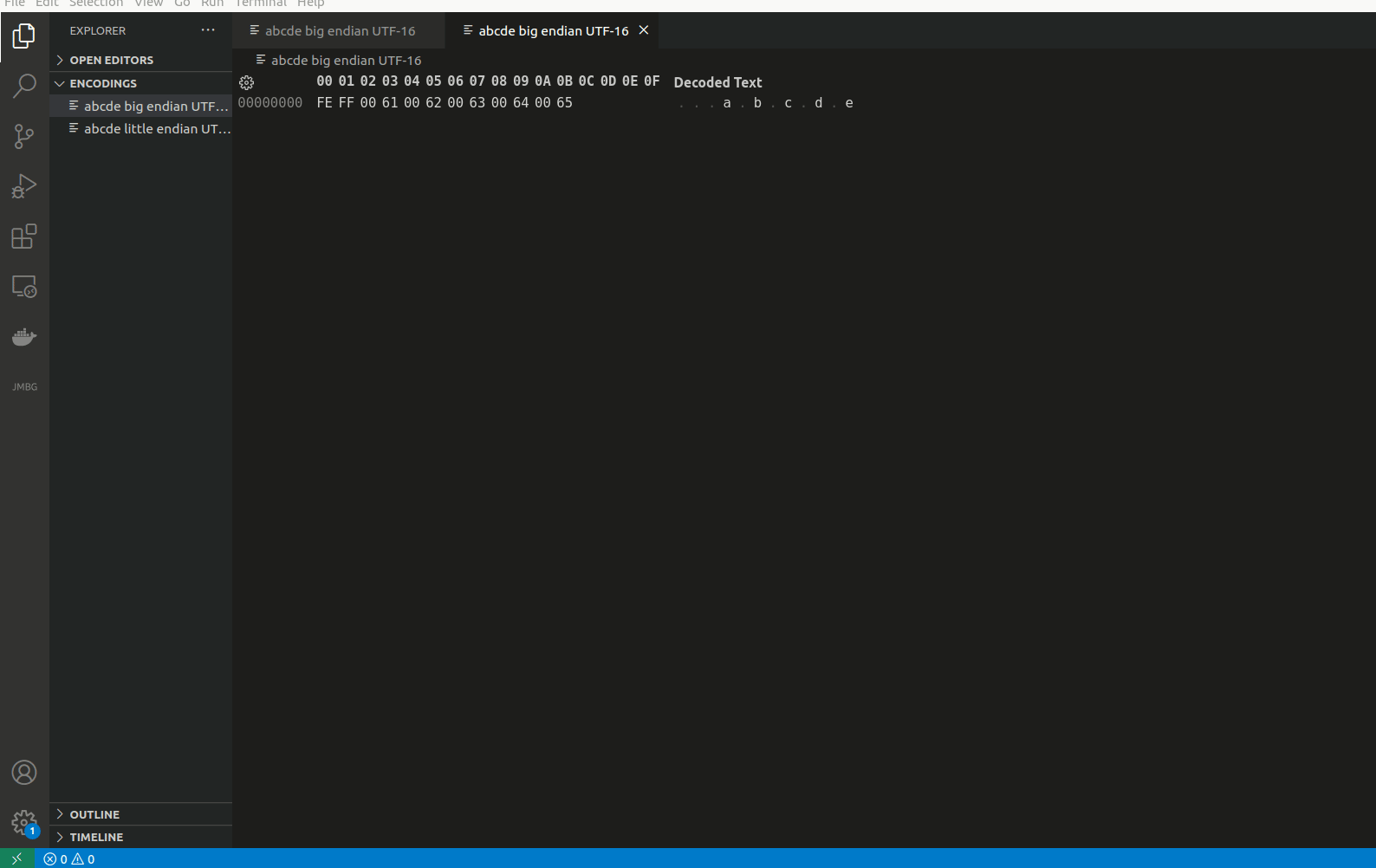
If BOM is not set for UTF-16, it is assumed that Big endian is used.
UTF-8
This brilliant encoding scheme is one of the most used today alongside UTF-16, because of its very useful features.
Code points that take 1 byte of size and are encoded with the same scheme as ASCII encoding. For all other code points, UTF-8 uses from 2 up to 4 bytes (even 6 in some cases), depending on the code point itself.
What this encoding allows as a bonus is backward compatibility with ASCII encoded files, as all ASCII characters would be read properly. This is not the case with UTF-32, UTF-16, and UCS-2 encoding schemes, as they expect the exact number of bytes per code point (4 for UTF-32, 2 for UCS-2 and 2-4 for UTF-16).
Also, programs that use ASCII encoding can read files written in the UTF-8 schema, as long as they used only ASCII characters.
What is the downside of the UTF-8 encoding scheme? It should be obvious by now, that it’s the fact that code points are variable in size, so it’s hard to index code points in a file (in other words searching for the n-th character in the file), in contrast to UTF-32 and UTF-16 encoding schemes.
Another downside is that it uses 50% more space than UTF-16 for East Asian text.
UTF-8 also has the nice property that ignorant old string-processing code that wants to use a single 0 byte as the null-terminator will not truncate strings, as is the case with other encoding schemes.
UTF-8 encoding algorithm
The encoding algorithm that is used for UTF-8 is very simple, yet brilliant!
It can be summarized in the following rules:
- If the code point is in the range of ASCII characters, it is encoded in the same way as ASCII. Simple as that!
- For other characters, we need to use more than one byte, in the following way:
- The first byte must start with the same number of zeros as the number of bytes that will be used for this code point, followed by a zero.
- Every other byte must start with
10. - Once we create such masked bytes, we fill in the binary form of the code point in data spaces.
As this was a mouthful, let’s go over some examples to better understand this process.
Example 1
Character A falls in a range of ASCII characters. Therefore, it’s encoded using ASCII encoding like this:
1
01000001
Example 2
Greek letter Φ has a Unicode code point U+03A6.
Its binary form is:
1
00000011 10100110
As we can see, it has more than 7 bits in size, hence we need to use step 2. in the algorithm for encoding this code point to UTF-8.
Let’s check if 2 bytes will be enough to encode this code point. In such a case, the first byte will have the following mask:
1
2
// Number of ones == number of bytes, then 0
110XXXXX
Next byte would have a mask:
1
10XXXXXX
If we count up X signs, we see that we have 11 spaces for binary representation of Unicode code point.
As our code point from example, Φ can fit in 10 binary digits, 2 bytes is enough for this code point.
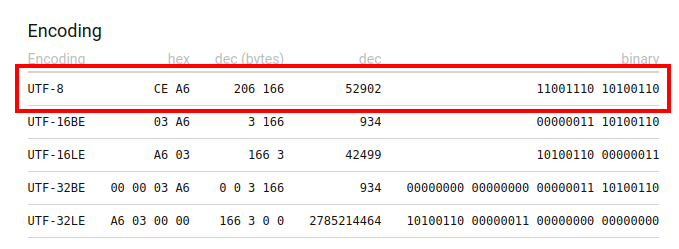
What is left to do is to replace masks with binary digits that represent our Unicode code point:
1
11001110 10100110
Or, in hexadecimal, we get CE A6.
If you check https://unicode-table.com/en/03A6/, you can verify we got the correct value. Yeah 🥳!
Example 3
For the final example, let’s take one more look at the 🚀 emoji.
Binary form:
1
00000000 00000001 11110110 10000000
As this one needs 17 bits, it will not fit in 2 bytes for the UTF-8 encoding.
It will not fit into 3 bytes as well, because:
1
1110XXXX 10XXXXXX 10XXXXXX
This gives us 16 bits of space, but we need 17.
So, we need 4 bytes:
1
11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
This gives us 3x6+3 = 21 bits of space for Unicode code points.
Now, let’s populate masked bits and we get:
1
11110000 10011111 10011010 10000000
Which is F0 9F 9A 80 in hexadecimal. You can verify it here: https://unicode-table.com/en/1F680/
UTF-8 encoding summary
Here is a summary of code point ranges and their respective UTF-8 byte sizes:
| Bits of code point | First code point | Last code point | Bytes in sequence | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 |
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx | |||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 31 | U+400000 | U+7FFFFFFF | 6 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
What about BOM for UTF-8?
For UTF-8 there is also a possibility to define BOM in the same way as for UTF-16.
We know that BOM code point is FE FF. Binary form is:
1
11111110 11111111
As we’ve seen in an exercise just before, since this code point is more than 8 bits in size, we need to use multiple bytes. In this case, we need to use 3 bytes, as it gives us 16 bits of space, which is exactly how much we need to represent this code point.
We already know that the first byte must start with several ones that represent how many bytes this code point requires by UTF-8 encoding (in this case 3), followed by zero. For other bytes, they must start with 10:
1
2
3
4
5
6
// First byte mask
1110xxxx
// Other bytes masks
10xxxxxx
10xxxxxx
So, complete mask for our FE FF code point is:
1
1110xxxx 10xxxxxx 10xxxxxx
Now what is left is to populate x signs with bits themselves. We finally get:
1
11101111 10111011 10111111
Or, in hexadecimal:
1
EF BB BF
If file is saved in UTF-8 with BOM encoding scheme, it’s first three bytes will be:
1
2
3
4
5
// Big Endian
EF BB BF
// Little Endian
BF BB EF
Here is another demo of a file saved in UTF-8 BOM encoding:

As is the case with UTF-16, if BOM is not present, assumed is Big Endian.
Programming languages character encodings
In most tutorials for beginners in any programming language, you learn how to print out the console famous “Hello world!” sentence.
As it would be overkill for a beginner student to learn all about character encodings, this information is usually left out.
But it’s very important to know that not all programming languages are Unicode aware (meaning they operate on a sequence of Unicode characters rather than ASCII characters).
Here is a list of some mainstream programming languages and their default character encodings:
| Programming language | Default character encoding | Unicode aware |
|---|---|---|
| C/C++ | ASCII | ❌ |
| Java | UTF-16 (first versions used UCS-2) | ✅ |
| C# | UTF-16 | ✅ |
| Javascript | UTF-16 | ✅ |
| PHP | ASCII | ❌ |
| Python 2 | ASCII | ❌ |
| Python 3 | UTF-8 | ✅ |
This overview shows only the default character encoding used by these programming languages, it does not mean they cannot process Unicode text. They all have support for Unicode, either through additional data types or 3rd party libraries.
The key point to take away from here is that you should be aware of the limitations your programming language has when processing data, otherwise you can get in all kinds of funny situations. For example, counting the number of characters in Unicode text that has at least one character outside the ASCII range using C++ char datatype would give you the wrong result.
DB Unicode support
For most DB engines there are, either SQL or NoSQL, there are settings per-database level where you can choose character encoding by yourself.
All modern DB engines have support for Unicode, but you need to be cautious when choosing encoding schema.
MySQL
For example, there is a case of MySQL server that has an encoding scheme called “utf8”, which is just an alias for “utfmb3”. What it represents is UTF-8 with Maximum Bytes 3.
As shown in section “UTF-8 encoding summary”, we can see that with 3 bytes you can store only a range from U+0000 up to U+FFFF, so-called BMP (Basic Multilingual Plane).
In MySQL, the encoding scheme “utf8” cannot store Unicode code points outside Basic Multilingual Plane!
Therefore, the recommended character encoding is “utf8mb4”, which allows up to 4 bytes in size.
Transmitting strings over the network
When sending data over a network, the recipient does not know the character encoding used to create that data. So, if you don’t specify it somehow, the recipient can only guess what encoding to use to read the content.
E-mail encoding
When sending e-mail messages you should (e-mail client actually) write a Content-Type HTTP header. It is used to indicate MIME type, where text can be one of the values. An example of UTF-8 encoding would be:
1
Content-Type: text/plain; charset="UTF-8"
HTML encoding
As for the HTML pages, the encoding scheme is set up inside the same HTML file, with a special tag.
1
2
3
4
5
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
...
Now you may wonder how a text processor (in this case web browser) can even read the first part of the HTML without knowing the character encoding used?
If you take a look at the code we just wrote, you can notice that all the characters used in this part of the file are in a range of ASCII printable characters. That allows for any ASCII-compatible encoding scheme (the vast majority of encoding schemes in use today) to read this part of the file.
After the charset is read by a web browser, it can switch to a different encoding scheme if needed.
meta tag for declaring charset in HTML should be the first thing in <head> tag, for 2 reasons:
- if something other than ASCII comes before this meta tag, you compromise the browser’s ability to read the proper charset and therefore the page can appear “broken”.
- as soon as the browser read the charset it will stop parsing the page and it will start from the beginning using the specified encoding scheme.
You may ask what happens if there is no charset defined in HTML? Did the browser try to guess the encoding, or it will just use some default encoding scheme? Well, browsers do try to guess the encoding based on statistics on how many times particular characters appear in a text. As you may assume, it was not very successful in achieving a good result.